[Pandas-1-] 타이타닉 데이터 셋 불러와서 가공 하기
아래 링크를 클릭 하면, 타이타닉 데이터 셋을 가져 올 수 있다.
Titanic - Machine Learning from Disaster | Kaggle
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com

저장 하려면 다음과 같이 가입을 해야된다.
구글 계정으로 간편하게 가입 할 수 있다.

구글 계정연동 하고 나면 다음과 같이 보인다. 타이타닉 데이터 샘플이나 IRIS data set은 기본적인 공부 코드에 이용 많이되니 저장 해 놓으면 두고 두고 쓸일 이 있을 것이다.
이제 Data를 열어 보자.
|
1
2
3
4
5
6
7
8
9
10
|
import pandas as pd
import numpy as np
df = pd.read_csv('train.csv')
print("프린트로 하여 출력")
print(df)
print("display로 출력")
display(df)
|
cs |
결과물
프린트로 데이터를 뽑으면 다음과 같이 보기 불편하다.
이럴 떄는 display를 사용 하면 좀 더 보기 용이 하다.

아래는 display로 출력 했을 때의 화면이다.

|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
print("컬럼정보 보기")
display(df.info())
print("데이터프레임 일부만 보기")
display(df.head())
display(df.head(20))
print("테이터 프레임 통계 데이터 보기")
display(df.describe())
|
cs |
추가로 컬럼 정보를 확인 해 보았다.
Dtype에는 각 컬럼의 타입을 확인 해 볼 수 있고
Non-null count에는 null data가 있는지 확인 해 볼 수 있다.
컬럼을 보면 Age, Cabin, Embarked에 null data가 있는 것을 확인 할 수 있다.

df.head()를 이용하면, 데이터를 일부만 볼 수 있다.
default값으로 5로 지정 되어 있어 위에서 부터 다섯개만 보인다.
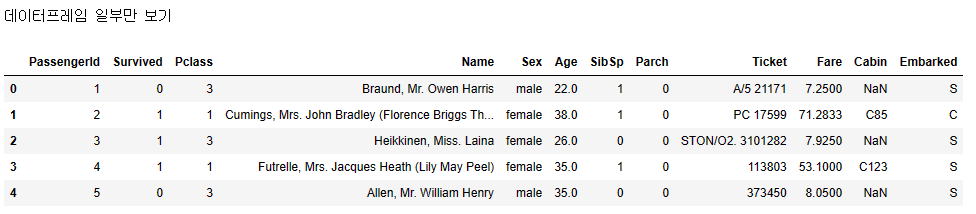
df.head(20) 이렇게 하면 20개 까지 data를 볼 수 있다.

df.describe()를 활용 하면, 통계값도 볼 수 있다.
각 컬럼 별로 계산 할 수 있는 통계값만 볼 수 있다.

특정 컬럼만 확인 할 수도 있다.
"Pclass" 컬럼만 확인 해 보자
|
1
2
3
4
5
6
7
|
print("Series 출력")
df['Pclass']
print("Pandas 출력")
df[['Pclass']]
|
cs |

판다스의 1차원 형태는 다음과 같이 볼 수 있다. 컬럼 명이 보이지 않는다.

2차원으로 보려면 다음과 같이 괄호를 하나 더 씌워 주면 된다.
|
1
2
3
|
print("컬럼내의 벨류값의 count")
print(df['Pclass'].value_counts())
|
cs |
value_counts()를 활용하면 카테고리컬한 데이터의 분포를 파악 하는데 도움이 된다.

df.max(), df.var()등을 활용 하면 통계값도 확인 할 수 있다.
오늘은 여기 까지 하고, 데이터를 쭉 이어서 추가로 가공 할 예정